PostgreSQL 9.3 + Pgpool-II
Decided to share with you the experience of configuring PostgreSQL 9.3 cluster consisting of two nodes, the management of which deals with pgpool-II without using Stream Replication (WAL). I hope someone will be interested.
Scheme:
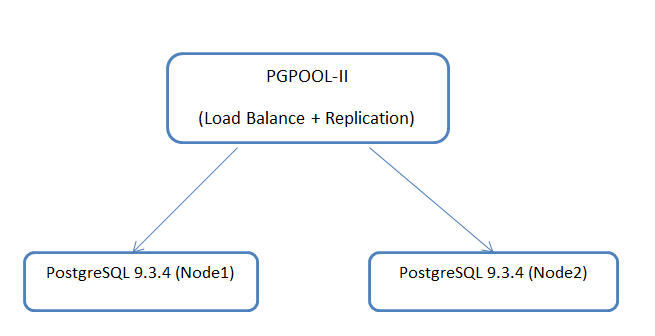
As You know, it will be two separate servers that will be managed by pgpool-II.
Configuration of nodes with PostgreSQL:
Both servers are identical in their hardware components.
the
Wheels:
the
Example,
the
Configuration node with pgpool-II:
the
Wheels:
the
About the installation of PostgreSQL in details I will not, because it is standard.
Configuring pgpool-II.
From the settings of pgpool-II, took the user manual from the official site: www.pgpool.net/pgpool-web/contrib_docs/simple_sr_setting2_3.3/index.html
I would like to draw the attention of only the most important points:
the
After setting up the configuration file, start the service of pgpool. You can also configure pgpooladmin to monitor the status of the node.
I did the instructions from here:
www.pgpool.net/docs/pgpoolAdmin/en/install.html
The status of the nodes with PostgreSQL can be viewed by running the command on pgpool:
the
Next, check the performance of our scheme — create an empty database via pgpool. This can be done in two ways:
1) using pgadmin, connect to the IP address of pgpool-II.
2) perform the command on the node with pgpool: createdb -p 9999 bench_replication
Cons:
the
Pros:
the
It is based on the instruction on the link: www.pgpool.net/pgpool-web/contrib_docs/simple_sr_setting2_3.3/index.html
Article based on information from habrahabr.ru
Scheme:
As You know, it will be two separate servers that will be managed by pgpool-II.
Configuration of nodes with PostgreSQL:
Both servers are identical in their hardware components.
the
-
the
- 4vCPU; the
- 16GB memory; the
- CentOS 6.5;
Wheels:
the
-
the
- 50 GB — system; the
- 100 GB pg_xlog the
- 500 GB — data directory
Example,
the
Filesystem Size Used Avail Use% Mounted on /dev/sda3 48G 7.4 G 38G 17% / tmpfs 7.8 G 0 7.8 G 0% /dev/shm /dev/sda1 194M 28M 157M 15% /boot /dev/sdb1 99G 4.9 G 89G 6% /var/lib/pgsql/9.3/data/pg_xlog /dev/sdc1 493G 234G 234G 50% /var/lib/pgsql/9.3/my_data
Configuration node with pgpool-II:
the
-
the
- 4vCPU; the
- 8GB memory; the
- CentOS 6.5;
Wheels:
the
-
the
- 50 GB — system;
About the installation of PostgreSQL in details I will not, because it is standard.
Configuring pgpool-II.
From the settings of pgpool-II, took the user manual from the official site: www.pgpool.net/pgpool-web/contrib_docs/simple_sr_setting2_3.3/index.html
I would like to draw the attention of only the most important points:
the
#------------------------------------------------------------------------------
# CONNECTIONS
#------------------------------------------------------------------------------
# - pgpool Connection Settings -
listen_addresses = '*'
port = 9999
socket_dir = '/tmp'
pcp_port = 9898
pcp_socket_dir = '/tmp'
# - Authentication -
enable_pool_hba = off
pool_passwd = "
log_destination = 'syslog'
#------------------------------------------------------------------------------
# REPLICATION MODE (pgpool Say that all received queries to be broadcast to all nodes of the cluster)
#------------------------------------------------------------------------------
replication_mode = on
replicate_select = on
insert_lock = on
lobj_lock_table = "
replication_stop_on_mismatch = off
failover_if_affected_tuples_mismatch = off
#------------------------------------------------------------------------------
# LOAD BALANCING MODE (pgpool Say that all SELECT queries to send to all cluster nodes)
#------------------------------------------------------------------------------
load_balance_mode = on
ignore_leading_white_space = on
white_function_list = "
black_function_list = 'nextval,setval'
follow_master_command = '/etc/pgpool-II/failover.sh %d "%h" %p %D %m %M "%H" %P'
#------------------------------------------------------------------------------
# FAILOVER AND FAILBACK
#------------------------------------------------------------------------------
failover_command = '/etc/pgpool-II/failover.sh %d %P %H %R'
failback_command = "
fail_over_on_backend_error = on
search_primary_node_timeout = 10
#------------------------------------------------------------------------------
# ONLINE RECOVERY (IN this case, online recovery, pgpool terms, means to return the node to the cluster pgpool. If one of the gcd will fall and lie for a long time, then dogonit this node up-to-date data will have to manually)
#------------------------------------------------------------------------------
recovery_user = 'postgres'
recovery_password = "
recovery_1st_stage_command = 'basebackup.sh'
recovery_2nd_stage_command = "
recovery_timeout = 90
client_idle_limit_in_recovery = 0
#------------------------------------------------------------------------------
# WATCHDOG
#------------------------------------------------------------------------------
# - Enabling -
use_watchdog = off
trusted_servers = 'IP-address-pgpool-host'
ping_path = '/bin'
wd_hostname = 'VRRIP IP. Single sign-on when using watchdog
wd_port = 9000
wd_authkey = "
delegate_IP = 'VRRIP'
ifconfig_path = '/home/apache/sbin'
if_up_cmd = 'ifconfig eth0:0 inet $_IP_$ netmask 255.255.255.0'
if_down_cmd = 'ifconfig eth0:0 down'
arping_path = '/home/apache/sbin'
arping_cmd = 'arping -U $_IP_$ -w 1'
clear_memqcache_on_escalation = on
wd_escalation_command = "
wd_lifecheck_method = 'heartbeat'
wd_interval = 10
wd_heartbeat_port = 9694
wd_heartbeat_keepalive = 2
wd_heartbeat_deadtime = 30
wd_life_point = 3
wd_lifecheck_query = 'SELECT 1'
wd_lifecheck_dbname = 'template1'
wd_lifecheck_user = 'nobody'
wd_lifecheck_password = "
ssl_key = "
ssl_cert = "
ssl_ca_cert = "
ssl_ca_cert_dir = "
listen_backlog_multiplier = 2
log_line_prefix = "
log_error_verbosity = 'DEFAULT'
client_min_messages = 'notice'
log_min_messages = 'warning'
database_redirect_preference_list = "
app_name_redirect_preference_list = "
allow_sql_comments = off
connect_timeout = 10000
check_unlogged_table = off
backend_hostname0 = 'the name of the first node'
backend_port0 = 5432
backend_weight0 = 1
backend_data_directory0 = '/var/lib/pgsql/9.3/data'
backend_flag0= 'ALLOW_TO_FAILOVER'
backend_hostname1 = 'the name of the second node'
backend_port1 = 5432
backend_weight1 = 1
backend_data_directory1 = '/var/lib/pgsql/9.3/data'
backend_flag1= 'ALLOW_TO_FAILOVER'
other_pgpool_hostname0 = "
other_pgpool_port0 =
other_wd_port0 =
heartbeat_destination0 = "
heartbeat_destination_port0 =
heartbeat_device0 = "
After setting up the configuration file, start the service of pgpool. You can also configure pgpooladmin to monitor the status of the node.
I did the instructions from here:
www.pgpool.net/docs/pgpoolAdmin/en/install.html
The status of the nodes with PostgreSQL can be viewed by running the command on pgpool:
the
pcp_node_info 10 "name pgpool-node" 9898 postgres postgres 0
pcp_node_info 10 "name pgpool-node" 9898 postgres postgres 1
Next, check the performance of our scheme — create an empty database via pgpool. This can be done in two ways:
1) using pgadmin, connect to the IP address of pgpool-II.
2) perform the command on the node with pgpool: createdb -p 9999 bench_replication
Cons:
the
-
the
- Synchronous replication the
- In case of failure of one of nod, on her return will have to sweat the
- is Sufficiently small that use this architecture the
- Block table
Pros:
the
-
the
- Logical replication, not go to the DBMS level, it reduces stress on the
- load Balancing the
- Caching of queries
the Union connections
It is based on the instruction on the link: www.pgpool.net/pgpool-web/contrib_docs/simple_sr_setting2_3.3/index.html



Комментарии
Отправить комментарий