Infrastructure Blekko: 800 servers, your crawler and Perl modules
New search engine Blekko began work a month and a half ago and quite naturally attracted the attention of experts. Not only thanks to innovative interface and lastelem, but in principle, still nowadays the launch of a new search engine overall profile — a rarity. Few people dare to compete with Google. In addition, it requires considerable financial investments.
Let's see what is the infrastructure Blekko, which in detail rasskazali CEO Richard Skrenta CTO Greg Lindahl.
Data center Blekko has about 800 servers, each with 64GB of RAM and eight SATA drives in the terabytes. System redundancy RAID is not being used at all, because RAID controllers greatly reduce the performance (800 MB/s for up to eight drives to 300-350 MB/s).
To avoid losing data, developers use a fully decentralized architecture and a number of unusual tricks.
First, they developed the "search modules", which simultaneously combines the functions of crawling, and analysis, and search results. Due to this, the cluster of 800 servers is maintained full decentralization. All servers are equal, there is no dedicated specialized clusters, for example, crawling.
The servers in the decentralized network to exchange data, so that each time a copy of the information blocks contains. Once the disk or server fails, the other servers notice it immediately and begin the process of "treatment", that is, the additional replication data from a lost system. This approach, according to Skrenta more effective than RAID.
If a disk fails, the engineer is in the data center and change it. With the number of disks of about 6,400 duty admins probably don't have a lot of sleep.
Servers index 200 million web pages a day, but only in the index over 3 billion documents. The frequency of updates ranges from several minutes to the main pages of popular news sites to 14 days. This option is clearly demonstrated in search results: Lastage /date you can see which pages were last indexed and how many seconds ago.
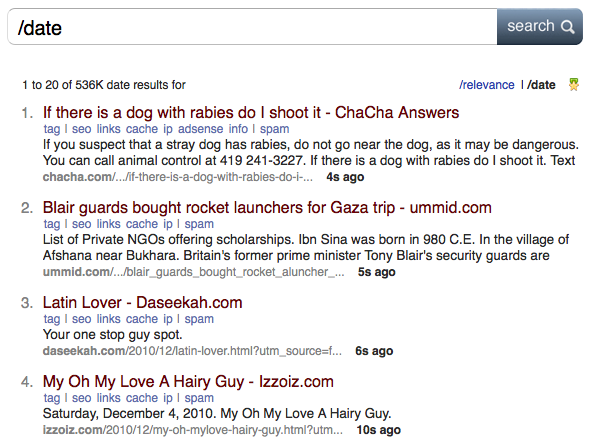
You can refresh the page and watch the crawler. It is seen that the addition of new content in results occurs with an interval in seconds. Even Google Caffeine does not provide such speed.
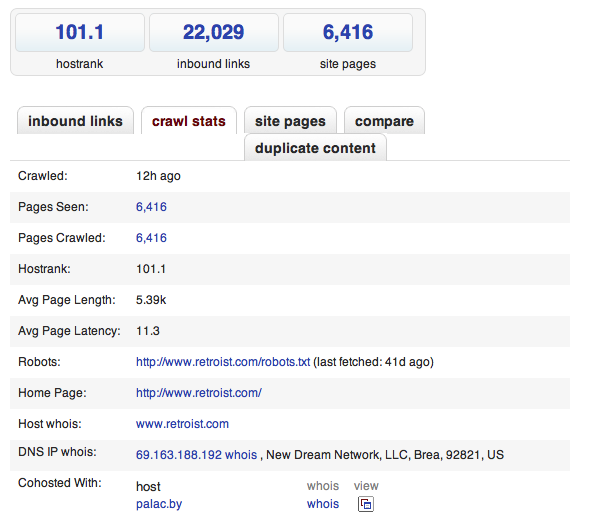
From a technical point of view, they managed to make such an implementation of MapReduce that works in small iterations and provides instant display of each iteration. It is possible to see if refresh SEO-stranichkuthat is attached to each search result.
The secret of success of this extraordinary decision — Perl. The developers say that they are extremely happy with our choice in the library there are CPAN modules for every taste, and each machine has over 200 modules. The server is CentOS and since they're all the same, it is possible to use an identical distribution.
Article based on information from habrahabr.ru
Let's see what is the infrastructure Blekko, which in detail rasskazali CEO Richard Skrenta CTO Greg Lindahl.
Data center Blekko has about 800 servers, each with 64GB of RAM and eight SATA drives in the terabytes. System redundancy RAID is not being used at all, because RAID controllers greatly reduce the performance (800 MB/s for up to eight drives to 300-350 MB/s).
To avoid losing data, developers use a fully decentralized architecture and a number of unusual tricks.
First, they developed the "search modules", which simultaneously combines the functions of crawling, and analysis, and search results. Due to this, the cluster of 800 servers is maintained full decentralization. All servers are equal, there is no dedicated specialized clusters, for example, crawling.
The servers in the decentralized network to exchange data, so that each time a copy of the information blocks contains. Once the disk or server fails, the other servers notice it immediately and begin the process of "treatment", that is, the additional replication data from a lost system. This approach, according to Skrenta more effective than RAID.
If a disk fails, the engineer is in the data center and change it. With the number of disks of about 6,400 duty admins probably don't have a lot of sleep.
Servers index 200 million web pages a day, but only in the index over 3 billion documents. The frequency of updates ranges from several minutes to the main pages of popular news sites to 14 days. This option is clearly demonstrated in search results: Lastage /date you can see which pages were last indexed and how many seconds ago.
You can refresh the page and watch the crawler. It is seen that the addition of new content in results occurs with an interval in seconds. Even Google Caffeine does not provide such speed.
From a technical point of view, they managed to make such an implementation of MapReduce that works in small iterations and provides instant display of each iteration. It is possible to see if refresh SEO-stranichkuthat is attached to each search result.
The secret of success of this extraordinary decision — Perl. The developers say that they are extremely happy with our choice in the library there are CPAN modules for every taste, and each machine has over 200 modules. The server is CentOS and since they're all the same, it is possible to use an identical distribution.

Комментарии
Отправить комментарий